ЕСОЗ - публічна документація
Medical events Technical Documentation
- Petro Lymych (Unlicensed)
Architecture
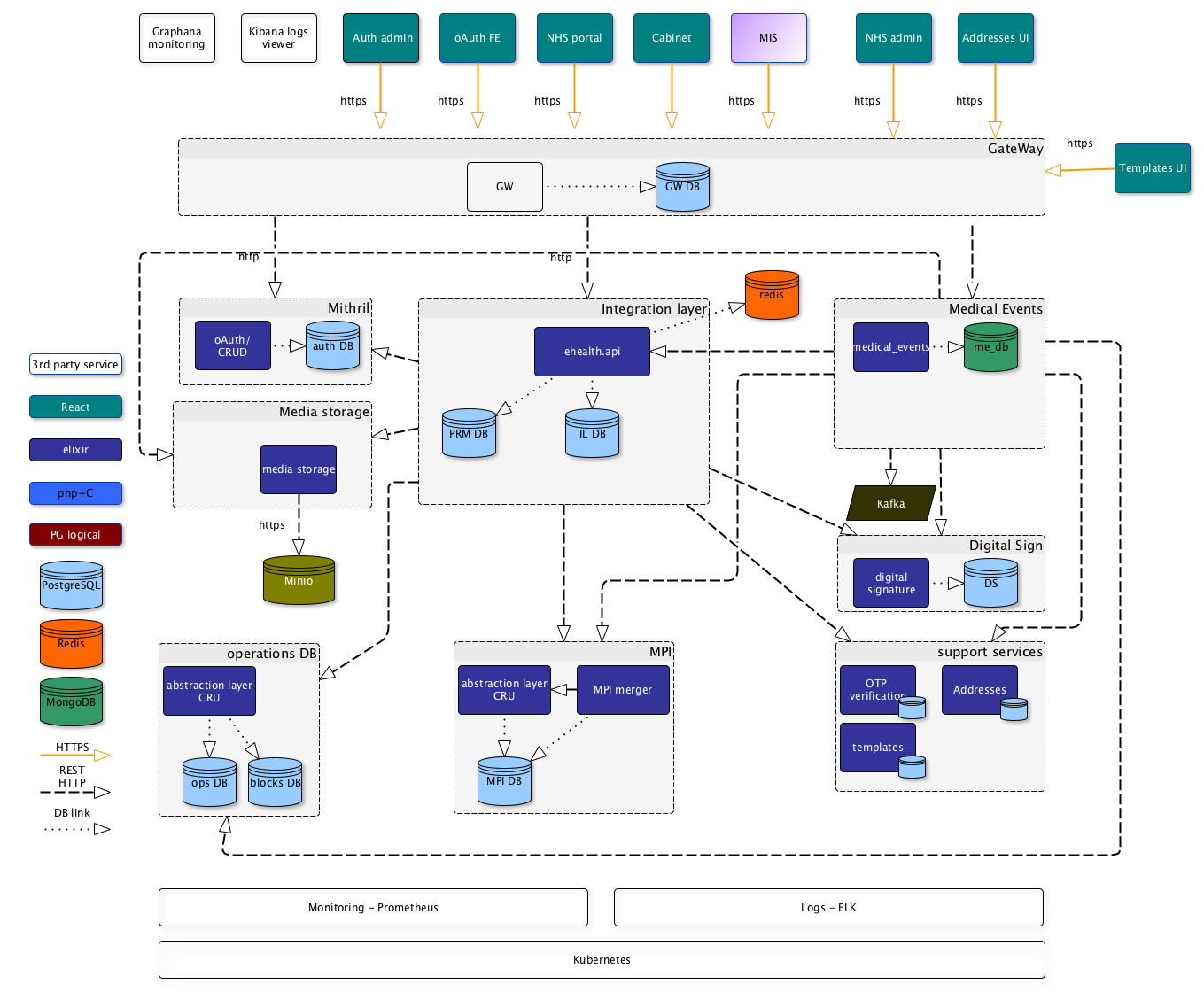
Performance requirements
Indicative Volumes that might be reached some day. System is not sized based on these volumes.
| Object | volume |
|---|---|
| Patients | 50.000.000 |
| Visit | up to 40.000.000.000 |
| Episode | up to 10.000.000.000 |
| Encounter | up to 40.000.000.000 |
| Observation | up to 500.000.000.000 |
| Condition | up to 500.000.000.000 |
| Allergy intolerance | 1.000.000.000 |
| Immunization | 1.000.000.000 |
Volumes prediction and HW-sizing calculation based on it - refer to the medical events sizing, sheet "Prod - Model4"
Async job processing Sequence diagram
Submit encounter job is processed in stages:
- Validation
- json validation
- create job in MongoDB
- package_create_job message type is created in Kafka medical_events topic
- package_create_job processing
- check that there is no jobs processing for the patient_id
- if not - put patient_id to processing queue (required to guarantee that new request of one patient will not be processed until the previous one has been completed)
- else -
- decode signed_content
- validation
- validation failed:
- update job.status == failed
- error code == 4xx
- save signed_content
- If error -
- update job.status == failed_with_error
- error_code == 500
- else create package_save_patient type in Kafka first_medical_events topic
- package_save_patient processing
- save patient data to medical_data MongoDB collection
- If error -
- update job.status == failed_with_error
- error_code == 500
- else - create package_save_conditions type in Kafka second_medical_events topic
- package_save_conditions processing
- save conditions to conditions MongoDB collection
- If error - consumer fails and after restart should process the same message
- else - create package_save_observations type in Kafka second_medical_events topic
- package_save_observations processing
- save observations to conditions MongoDB collection
- If error - consumer fails and after restart should process the same message
- else - update_job_status message is created
- Update job status processing
- remove patient_id from processing queue
- update job status to processed
- If error - consumer fails and after restart should process the same message
- else - done
Decisions
| # | Statement | Comment |
|---|---|---|
| 1. | All the medical event POST/PUT operations should be async | Duration to process new records creation is not so critical for the medical service providers. They do have already all the data. Anyway it still should be processed in seconds/minutes, not hours/days. |
2. | GET operations will be sync | |
| 3. | Kafka will be used as a queue manager for the async operations |
|
| 4. | MongoDB will be used as a storage of the medical events data |
|
| 5. | Data validation and consistancy should be guaranteed on the application level | Application should ensure that operations will not be performed partially. |
| 6. | Medical events - new repository |
|
| 7. | Medical data can be accessed via API only by patient. There is no way to get the medical data of multiple patients via single call |
|
| 8. | We do split the medical data into three collections:
|
|
| 9. | We do split the storing data structure and presentation views (requests/responses) |
|
| 10. | We do guarantee jobs processing sequence for one patient_id. Not for all the jobs |
|
| 11. | ME database shouldn't store MPI_ID. Patient_id in ME will be encrypted using secret key. |
|
Limitations
- Medical data profile of one patient (encounters, visits, episodes, allergy intolerance, immunizations) shouldn't exceed 16 Mbytes (~700-1000 encounters)
- Medical data can be accessed via API only by patient_id and via patient context. There is no way to get the medical data of multiple patients via single call
- System's architecture provides possibility to operate in the 24/7 mode. But in case if the master MongoDB node is down, there might be a downtime (up to minutes). We still do need the system maintenance time slots.
- MongoDB limitations. The most important ones:
- The maximum BSON document size is 16 megabytes.
- MongoDB supports no more than 100 levels of nesting for BSON documents.
- The total size of an index entry, which can include structural overhead depending on the BSON type, must be less than 1024 bytes.
- A single collection can have no more than 64 indexes.
- There can be no more than 31 fields in a compound index.
- Multikey indexes cannot cover queries over array field(s).
Database size: The MMAPv1 storage engine limits each database to no more than 16000 data files. This means that a single MMAPv1 database has a maximum size of 32TB. Setting the storage.mmapv1.smallFiles option reduces this limit to 8TB.
- Data Size: Using the MMAPv1 storage engine, a single
mongodinstance cannot manage a data set that exceeds maximum virtual memory address space provided by the underlying operating system. For Linux journaled data size of 64 TB - Replica sets can have up to 50 members.
Covered Queries in Sharded Clusters -Starting in MongoDB 3.0, an index cannot cover a query on a sharded collection when run against amongosif the index does not contain the shard key, with the following exception for the_idindex: If a query on a sharded collection only specifies a condition on the_idfield and returns only the_idfield, the_idindex can cover the query when run against amongoseven if the_idfield is not the shard key.- MongoDB does not support unique indexes across shards, except when the unique index contains the full shard key as a prefix of the index. In these situations MongoDB will enforce uniqueness across the full key, not a single field.
A shard key cannot exceed 512 bytes.
Shard Key Index TypeA shard key index can be an ascending index on the shard key, a compound index that start with the shard key and specify ascending order for the shard key, or a hashed index.
A shard key index cannot be an index that specifies a multikey index, a text index or a geospatial index on the shard key fields.
- Shard Key is Immutable
Open questions
| # | Question | Answer |
|---|---|---|
| 1. | Failed jobs processing | there are only two possible results of job processing: processed, error. Both of them mean that job has been successfully processed. |
| 2. | Jobs are processed FIFO. But it means that next job will not be processed until the current one is completed. It means that the whole system might block itself in case of problems of processing a single record. | in case if internal server or service error happens (50x), it will be forwarded to client. Option to be considered: put message back to the queue or move it to error queue. But in this case order processing cannot be guaranteed. |
Related content
ЕСОЗ - публічна документація